Snowflake data schema in dimensional modelling
When setting up a database, one of the first decisions you’ll face is how to organise your data. Two popular options are the snowflake schema and the star schema. In this article, we’ll break down what a snowflake data schema is, why it matters, and how it compares to a star schema. Whether you’re just starting with dimensional modeling or looking to improve your data setup, this guide will give you clear and practical insights to help you make the best choice.
What is a snowflake data schema?
ℹ️ A snowflake data schema is a way of organising data in a database or warehouse. Its structure is named after a snowflake, because its dimension tables branch out from one central fact table, resembling the shape of a snowflake. In a snowflake schema, data gets normalised by splitting it into smaller, related tables, reducing redundancy and saving storage space.
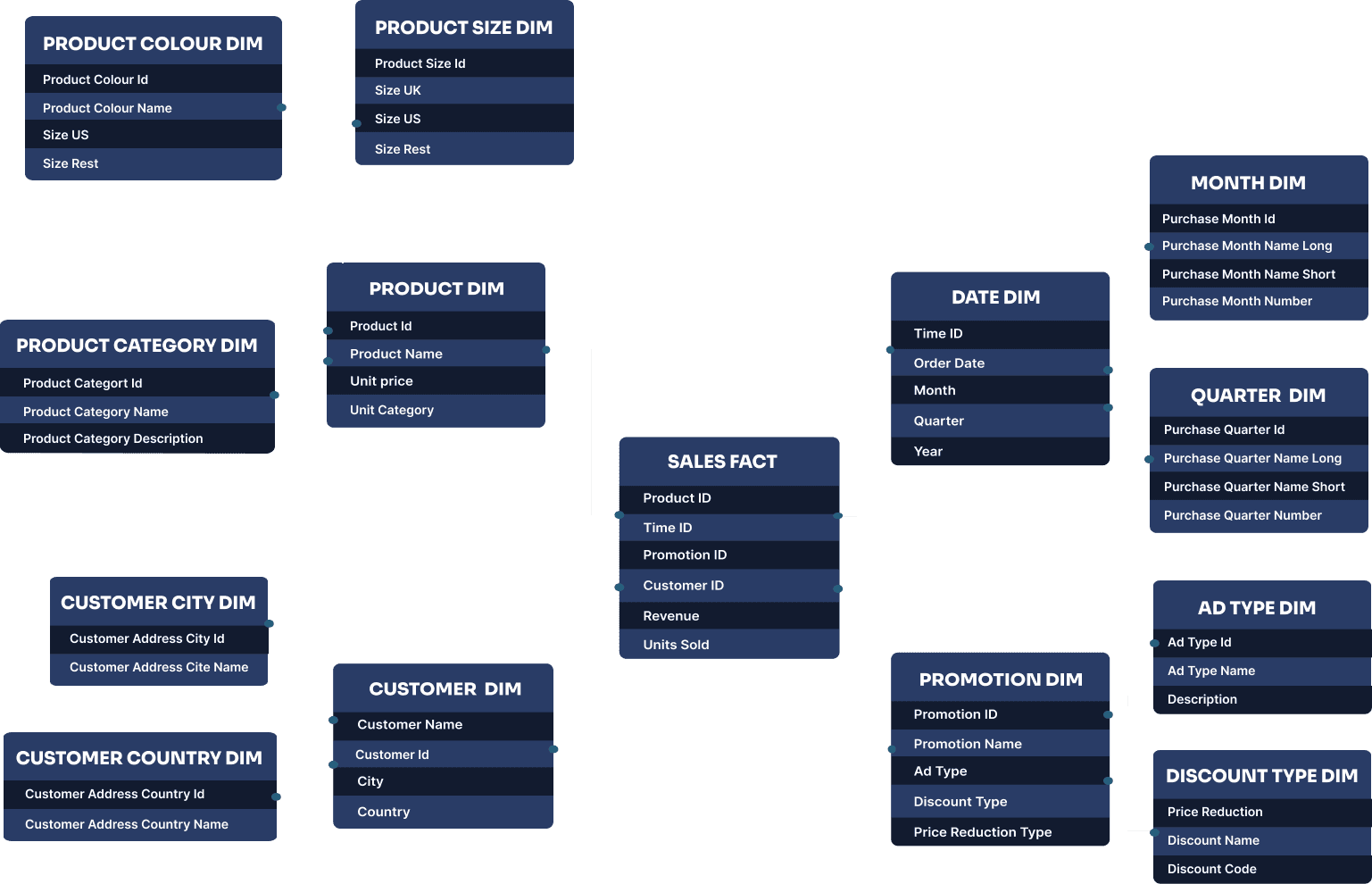
The example above illustrates how a snowflake schema organises data in a way that focuses on saving storage space and keeping everything consistent. It does this by breaking dimension tables into smaller, related tables, which reduces duplication and ensures that updates are reflected everywhere they’re needed.
Why use a snowflake data schema?
While snowflake data schemas can make queries a bit trickier because of the extra joins between tables, they are crucial when working with large datasets where storage efficiency and accuracy are key. They’re most commonly used in industries like finance, healthcare, and retail, where getting these details right is a high priority.
Take the retail scenario, for example. Instead of having one big table for all product details, a snowflake schema splits it into smaller tables for product categories, brands, and suppliers. This makes it easier to manage and ensures that if a supplier’s details change, those updates automatically show up wherever that supplier is referenced.
How a snowflake schema is different from a star schema
A snowflake schema and a star schema are both used in dimensional modeling, but they differ in structure and use cases:
| Aspect | Star Schema | Snowflake Schema |
|---|---|---|
| Structure | Central fact table connected directly to dimension tables, forming a star-like shape. | Normalises dimension tables into multiple related tables, creating a snowflake-like structure. |
| Complexity | Simpler and easier to understand, ideal for quick analysis and reporting. | More complex due to normalisation, making querying more challenging. |
| Storage Efficiency | May require more storage due to denormalised data. | Saves storage space by reducing redundancy through normalisation. |
| Performance | Optimised for query performance, especially in analytical tools like Power BI. | May have slower query performance due to the need for more joins between tables. |
In summary, star schemas are best suited for fast analysis and simpler use cases, while snowflake schemas are ideal for scenarios requiring strict data consistency and storage efficiency. Below, we’ll expand on which usecases fit a snowflake schema best.
When to use a snowflake schema?
You should use a snowflake schema when data normalisation is a priority, such as in scenarios where storage efficiency or strict data consistency is critical. This is common in industries like finance, healthcare, and retail. For example, in the healthcare industry, patient data might be normalised into separate tables for personal details, medical history, and billing information to ensure data consistency and reduce redundancy.
Snowflake schemas are also useful when handling facts at sub-grains of a dimension. For instance, in a retail scenario, you might have a central fact table for sales transactions, but the product dimension could be normalised into separate tables for product categories, brands, and suppliers. This allows for more granular data management and ensures that updates to one part of the dimension (e.g., a supplier’s details) are reflected across the schema.
If your data source is already normalised, building a snowflake schema can be more straightforward. For example, if you’re working with a relational database where tables are already split into smaller, related entities, adopting a snowflake schema might save time and effort compared to denormalising the data into a star schema.
However, while snowflake schemas offer these advantages, they can increase model complexity and make queries harder to write. For analytical tools like Power BI, which are optimised for star schemas, snowflake schemas should be used sparingly and only when necessary. If your dataset is small and has a limited scope, you might not need to worry too much about speed or efficiency. In this case, building a snowflake schema might be quicker, however, be cautious of quick fixes, as there’s often nothing more permanent than a temporary solution. Those “temporary” snowflake data models can quickly turn into Frankenstein’s monster over time, making future updates and feature requests a nightmare.
A snowflake data schema stands out for its ability to save storage space and maintain data consistency, making it a great choice for industries where these factors are crucial. Its complexity and the potential for slower query performance, however, mean it’s not always the best option for every situation. Always weigh the trade-offs between storage efficiency and query performance when deciding on the schema design.
When should I choose a snowflake schema over a star schema?
+What are the trade-offs of using a snowflake schema?
+About the author

See Bragi in action
Explore how Bragi can optimise your data architecture
Speak directly to Bragi’s co-founders, not a sales agent, and explore how Bragi can automate your data processes and transform your data workflows.